Note
Click here to download the full example code
MCMC sampling#
In this example, we demonstrate how to perform uncertainty quantification (UQ) using parallel tempered MCMC (PTMCMC). We use a Stillinger-Weber (SW) potential for silicon that is archived in OpenKIM.
For simplicity, we only set the energy-scaling parameters, i.e., A and lambda as
the tunable parameters. Furthermore, these parameters are physically constrained to be
positive, thus we will work in log parameterization, i.e. log(A) and log(lambda).
These parameters will be calibrated to energies and forces of a small dataset,
consisting of 4 compressed and stretched configurations of diamond silicon structure.
To start, let’s first install the SW model:
$ kim-api-collections-management install user SW_StillingerWeber_1985_Si__MO_405512056662_006
See also
This installs the model and its driver into the User Collection. See
Install a model for more information about installing KIM models.
from multiprocessing import Pool
import numpy as np
from corner import corner
from kliff.calculators import Calculator
from kliff.dataset import Dataset
from kliff.dataset.weight import MagnitudeInverseWeight
from kliff.loss import Loss
from kliff.models import KIMModel
from kliff.models.parameter_transform import LogParameterTransform
from kliff.uq import MCMC, autocorr, mser, rhat
from kliff.utils import download_dataset
Before running MCMC, we need to define a loss function and train the model. More detail information about this step can be found in Train a Stillinger-Weber potential and Parameter transformation for the Stillinger-Weber potential.
# Instantiate a transformation class to do the log parameter transform
param_names = ["A", "lambda"]
params_transform = LogParameterTransform(param_names)
# Create the model
model = KIMModel(
model_name="SW_StillingerWeber_1985_Si__MO_405512056662_006",
params_transform=params_transform,
)
# Set the tunable parameters and the initial guess
opt_params = {
"A": [["default", -8.0, 8.0]],
"lambda": [["default", -8.0, 8.0]],
}
model.set_opt_params(**opt_params)
model.echo_opt_params()
# Get the dataset and set the weights
dataset_path = download_dataset(dataset_name="Si_training_set_4_configs")
# Instantiate the weight class
weight = MagnitudeInverseWeight(
weight_params={
"energy_weight_params": [0.0, 0.1],
"forces_weight_params": [0.0, 0.1],
}
)
# Read the dataset and compute the weight
tset = Dataset(dataset_path, weight=weight)
configs = tset.get_configs()
# Create calculator
calc = Calculator(model)
ca = calc.create(configs)
# Instantiate the loss function
residual_data = {"normalize_by_natoms": False}
loss = Loss(calc, residual_data=residual_data)
# Train the model
loss.minimize(method="L-BFGS-B", options={"disp": True})
model.echo_opt_params()
Out:
#================================================================================
# Model parameters that are optimized.
# Note that the parameters are in the transformed space if
# `params_transform` is provided when instantiating the model.
#================================================================================
A 1
2.7268620056558381e+00 -8.0000000000000000e+00 8.0000000000000000e+00
lambda 1
3.8184197679684773e+00 -8.0000000000000000e+00 8.0000000000000000e+00
/home/yonatank/.local/lib/python3.8/site-packages/numpy/linalg/linalg.py:2500: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
x = asarray(x)
2022-08-10 17:00:23.489 | INFO | kliff.dataset.dataset:_read:398 - 4 configurations read from /home/yonatank/modules/kliff/examples/Si_training_set_4_configs
2022-08-10 17:00:23.493 | INFO | kliff.calculators.calculator:create:107 - Create calculator for 4 configurations.
2022-08-10 17:00:23.494 | INFO | kliff.loss:minimize:290 - Start minimization using method: L-BFGS-B.
2022-08-10 17:00:23.496 | INFO | kliff.loss:_scipy_optimize:404 - Running in serial mode.
2022-08-10 17:00:23.675 | INFO | kliff.loss:minimize:292 - Finish minimization using method: L-BFGS-B.
#================================================================================
# Model parameters that are optimized.
# Note that the parameters are in the transformed space if
# `params_transform` is provided when instantiating the model.
#================================================================================
A 1
2.7269268430321811e+00 -8.0000000000000000e+00 8.0000000000000000e+00
lambda 1
3.8183682461406869e+00 -8.0000000000000000e+00 8.0000000000000000e+00
'#================================================================================\n# Model parameters that are optimized.\n# Note that the parameters are in the transformed space if \n# `params_transform` is provided when instantiating the model.\n#================================================================================\n\nA 1\n 2.7269268430321811e+00 -8.0000000000000000e+00 8.0000000000000000e+00 \n\nlambda 1\n 3.8183682461406869e+00 -8.0000000000000000e+00 8.0000000000000000e+00 \n\n'
To perform MCMC simulation, we use MCMC.This class interfaces with
ptemcee Python package to run PTMCMC, which utilizes the affine invariance property
of MCMC sampling. We simulate MCMC sampling at several different temperatures to
explore the effect of the scale of bias and overall error bars.
# Define some variables that correspond to the dimensionality of the problem
ntemps = 4 # Number of temperatures to simulate
ndim = calc.get_num_opt_params() # Number of parameters
nwalkers = 2 * ndim # Number of parallel walkers to simulate
We start by instantiating MCMC. This requires Loss
instance to construct the likelihood function. Additionally, we can specify the prior
(or log-prior to be more precise) via the logprior_fn argument, with the default
option be a uniform prior that is bounded over a finite range that we specify via the
logprior_args argument.
Note
When user uses the default uniform prior but doesn’t specify the bounds, then the
sampler will retrieve the bounds from the model
(see set_opt_params()). Note that an error will be
raised when the uniform prior extends to infinity in any parameter direction.
To specify the sampling temperatures to use, we can use the arguments ntemps and
Tmax_ratio to set how many temperatures to simulate and the ratio of the highest
temperature to the natural temperature  , respectively. The default values of
, respectively. The default values of
ntemps and Tmax_ratio are 10 and 1.0, respectively. Then, an internal function
will create a list of logarithmically spaced points from  to
to
 . Alternatively, we can also give a list of
the temperatures via
. Alternatively, we can also give a list of
the temperatures via Tladder argument, which will overwrites ntemps and
Tmax_ratio.
Note
It has been shown that including temperatures higher than helps the
convergence of walkers sampled at .
The sampling processes can be parallelized by specifying the pool. Note that the pool
needs to be declared after instantiating MCMC, since the posterior
function is defined during this process.
# Set the boundaries of the uniform prior
bounds = np.tile([-8.0, 8.0], (ndim, 1))
# It is a good practice to specify the random seed to use in the calculation to generate
# a reproducible simulation.
seed = 1717
np.random.seed(seed)
# Create a sampler
sampler = MCMC(
loss,
ntemps=ntemps,
logprior_args=(bounds,),
random=np.random.RandomState(seed),
)
# Declare a pool to use parallelization
sampler.pool = Pool(nwalkers)
Note
As a default, the algorithm will set the number of walkers for each sampling
temperature to be twice the number of parameters, but we can also specify it via
the nwalkers argument.
To run the MCMC sampling, we use run_mcmc(). This function requires
us to provide initial states  for each temperature and walker. We also need
to specify the number of steps or iterations to take.
for each temperature and walker. We also need
to specify the number of steps or iterations to take.
Note
The initial states need to be an array with shape (K, L, N,), where
K, L, and N are the number of temperatures, walkers, and parameters,
respectively.
# Initial starting point. This should be provided by the user.
p0 = np.empty((ntemps, nwalkers, ndim))
for ii, bound in enumerate(bounds):
p0[:, :, ii] = np.random.uniform(*bound, (4, 4))
# Run MCMC
sampler.run_mcmc(p0, 5000)
sampler.pool.close()
# Retrieve the chain
chain = sampler.chain
The resulting chains still need to be processed. First, we need to discard the first few
iterations in the beginning of each chain as a burn-in time. This is similar to the
equilibration time in a molecular dynamic simulation before we can start the
measurement. KLIFF provides a function to estimate the burn-in time, based on the
Marginal Standard Error Rule (MSER). This can be accessed via
mser().
# Estimate equilibration time using MSER for each temperature, walker, and dimension.
mser_array = np.empty((ntemps, nwalkers, ndim))
for tidx in range(ntemps):
for widx in range(nwalkers):
for pidx in range(ndim):
mser_array[tidx, widx, pidx] = mser(
chain[tidx, widx, :, pidx], dmin=0, dstep=10, dmax=-1
)
burnin = int(np.max(mser_array))
print(f"Estimated burn-in time: {burnin}")
Out:
Estimated burn-in time: 480
Note
mser() only compute the estimation of the burn-in time for
one single temperature, walker, and parameter. Thus, we need to calculate the burn-in
time for each temperature, walker, and parameter separately.
After discarding the first few iterations as the burn-in time, we only want to keep
every  -th iteration from the remaining chain, where is the
autocorrelation length, to ensure uncorrelated samples.
This calculation can be done using
-th iteration from the remaining chain, where is the
autocorrelation length, to ensure uncorrelated samples.
This calculation can be done using autocorr().
# Estimate the autocorrelation length for each temperature
chain_no_burnin = chain[:, :, burnin:]
acorr_array = np.empty((ntemps, nwalkers, ndim))
for tidx in range(ntemps):
acorr_array[tidx] = autocorr(chain_no_burnin[tidx], c=1, quiet=True)
thin = int(np.ceil(np.max(acorr_array)))
print(f"Estimated autocorrelation length: {thin}")
Out:
Estimated autocorrelation length: 15
Note
acorr() is a wrapper for emcee.autocorr.integrated_time,
As such, the shape of the input array for this function needs to be (L, M, N,),
where L, M, and N are the number of walkers, steps, and parameters,
respectively. This also implies that we need to perform the calculation for each
temperature separately.
Finally, after obtaining the independent samples, we need to assess whether the
resulting samples have converged to a stationary distribution, and thus a good
representation of the actual posterior. This is done by computing the potential scale
reduction factor (PSRF), denoted by  . The value of
declines to 1 as the number of iterations goes to infinity. A common threshold is about
1.1, but higher threshold has also been used.
. The value of
declines to 1 as the number of iterations goes to infinity. A common threshold is about
1.1, but higher threshold has also been used.
# Assess the convergence for each temperature
samples = chain_no_burnin[:, :, ::thin]
threshold = 1.1 # Threshold for rhat
rhat_array = np.empty(ntemps)
for tidx in range(ntemps):
rhat_array[tidx] = rhat(samples[tidx])
print(f"$\hat{{r}}^p$ values: {rhat_array}")
Out:
$\hat{r}^p$ values: [0.99832965 1.07774255 1.10594832 1.07248159]
Note
rhat() only computes the PSRF for one temperature, so that
the calculation needs to be carried on for each temperature separately.
Notice that in this case,  for all temperatures. When this
criteria is not satisfied, then the sampling process should be continued. Note that
some sampling temperatures might converge at slower rates compared to the others.
for all temperatures. When this
criteria is not satisfied, then the sampling process should be continued. Note that
some sampling temperatures might converge at slower rates compared to the others.
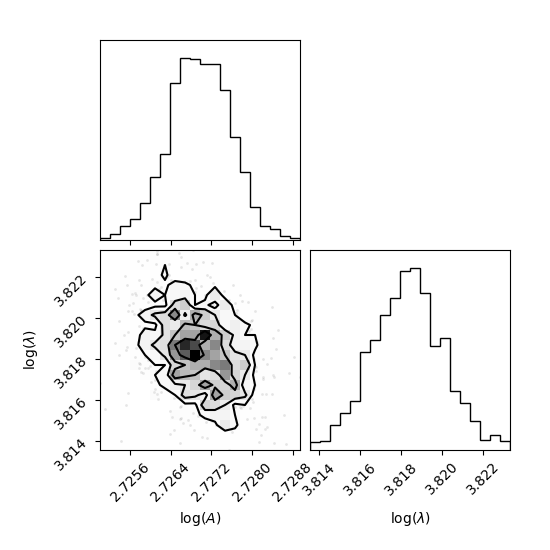
After obtaining the independent samples from the MCMC sampling, the uncertainty of the parameters can be obtained by observing the distribution of the samples. As an example, we will use corner Python package to present the MCMC result at sampling temperature 1.0 as a corner plot.
# Plot samples at T=1.0
corner(samples[0].reshape((-1, ndim)), labels=[r"$\log(A)$", r"$\log(\lambda)$"])
Out:
<Figure size 550x550 with 4 Axes>
Note
As an alternative, KLIFF also provides a wrapper to emcee. This can be accessed by
setting sampler="emcee" when instantiating MCMC. For further
documentation, see EmceeSampler.
Total running time of the script: ( 3 minutes 14.012 seconds)